为什么科研项目值得我们花功夫?
2013-08-21
我在任何技术上都不是什么很强的人,我只不过是知道多一些东西以及达到它们的途径而已。
为什么这个项目值得我们花功夫?
这些天我睡得很晚,躺在床上睡不着,很久没有这样的感觉了。我随手在weibo做了一些搜索,我发现挺多与我们项目相关的东西,这也是我写这篇东西的主要原因。另外一个原因是,我们的进度太慢了,这不应该;一方面有我工作的失责,另一方面是我自己本身也没有做出表率。前者是项目管理,后者是自我管理。
我想写一些东西给我的伙伴们,这是我的第一个团队。我会先从介绍我的所见所闻开始,进一步地,与大家交流我对于此科研训练项目的价值的思考;其后我从自我超越的角度,去看知识、技术和人品。目的,目的是希望我们可以互相监督,一起进步。
关于项目的潜在价值与项目管理
大牛挖坑,小牛灌水
互联网金融
随着阿里巴巴的大战略,互联网金融成为一个新兴概念,并且相关板块的公司已在A股市场上,用价格反映了投资者对这个行业的态度。这是一个很新的概念,随着大数据时代的到来迅速成长,并伴随相关技术的成熟发展而使一些ideas成为可能。
- 股票雷达 我们先简要介绍这个公司,给大家一个intuition,再用该公司的一则招聘信息做总结。 stockrador 现在我们再看一下公司的实习生招聘信息:算法/数据挖掘工程师

这里我们留意到这些信息: 自然语言处理 这是互联网金融的一个特点。以往的量化投资策略,往往采用容易数量化的东西去做模型;但随着互联网,尤其是微博的发展,网络上的文本信息(unstructured data)蕴含着很多信息。因为有很多人会在自己的weibo上发表对股市的看法,个股点评等等;这些sentiment data代表着市场信号,可以用来建模,有一种称为“事件驱动模型”的技术,便是研究特定事件对资本市场的影响的。
数据挖掘 数据挖掘,机器学习是这一块的重要技术。我在Coursera上跟进过Prof.Andrew的Machine Learning,期间学习了包括Linear Regression, Logistic Regression, Neural Network, Support Vector Machines, Dimensionality Reduction, Recommmender Systems, Large Scale Machine Learning等话题。虽然课讲的不深,但给了学生进一步深入算法的技术基础和认识基础。
大型抓取系统 我想这个就是爬虫,对,它看似很不起眼。但容易明白,模型的好坏与抓取到的内容直接相关。抓取的信息量,时效性都是评价抓取系统性能的指标。
点评与思考
真正到了工作岗位上,一定不可能让我们只会用一些工具的,一定是需要定制功能的。感谢开源,若不是有GitHub和无私的程序员,我们的项目根本不可能展开;从爬虫,到分词工具... 公司不会要我们用GooSeeker去抓取内容的,它性能不够。但我提到过的Scrapy一定是最佳的Python开源爬虫,它可定制性强,性能也更好。只不过因为不熟悉Python,我们都却步了,这样不好。
- EverString
这家公司做的事情更有意思,且更商业化和包容。这便是我们上面提到过的“事件驱动策略”
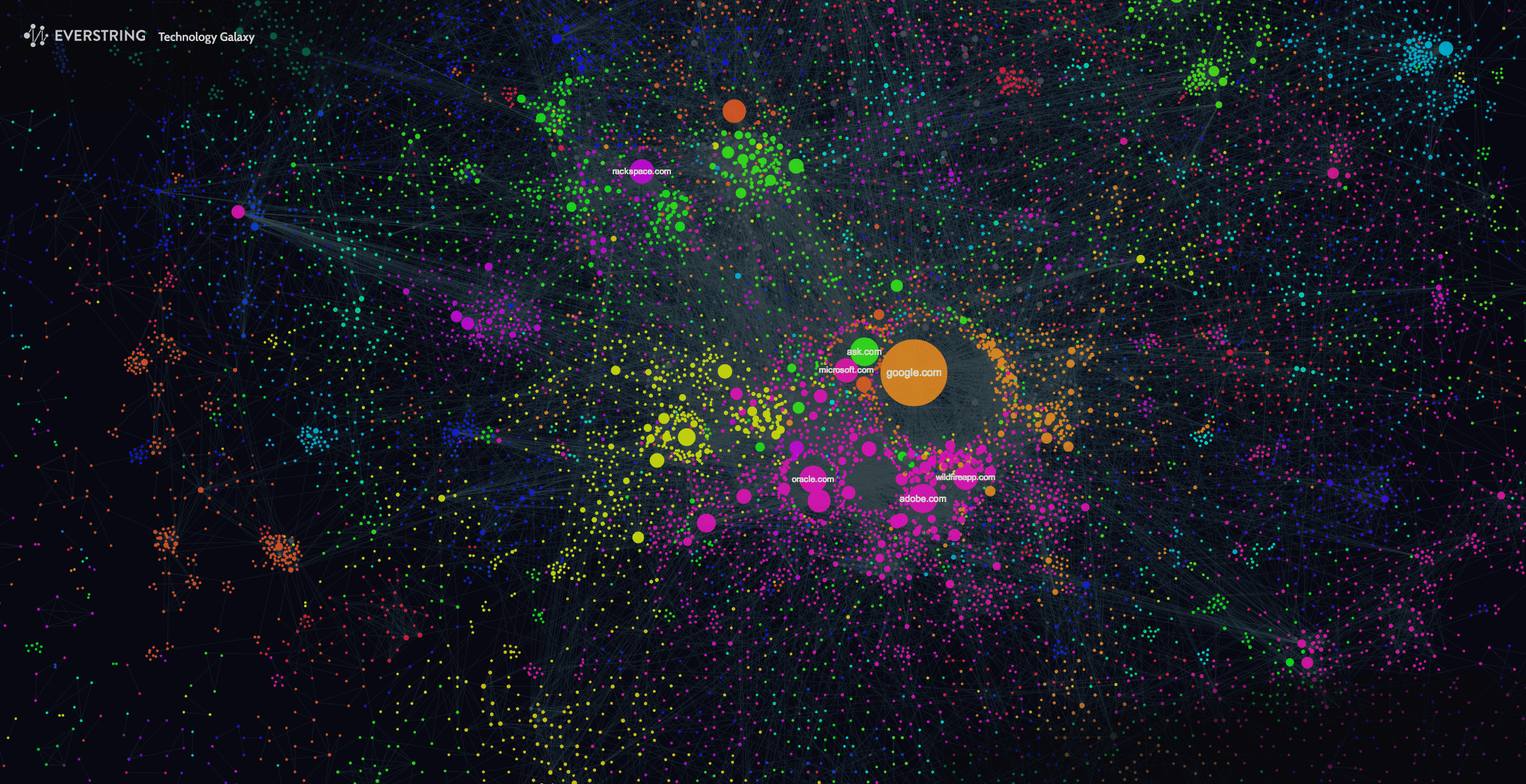
这张图是否很熟悉?我想这必定是社会网络分析,但有更多东西需要我们进一步挖掘。
- Predict short term movements in stock prices using news and sentiment data provided by RavenPack
The Big Data Combine engineered by BattleFin are rapid fire, live tryouts for computer scientists with elite predictive analytic skills intent on monetizing their models. The first stage of the competition is a predictive modeling competition that requires participants to develop a model that predicts stock price movements using sentiment data provided by RavenPack. Traders, analysts and investors are always looking for techniques to better predict price movements. Knowing whether a security will increase or decrease allows traders to make better investment decisions and manage risk more effectively.
This competition is designed to identify people with the talent to create a predictive model using financial data. Competitors are given intraday trading data showing stock price movements at 5 minute intervals and asked to predict the change two hours in the future. The winners of the predictive modeling phase are invited to the "live" Big Data Combine tryouts in Miami, FL. Up to 12 finalists will be selected to compete in the live event in Miami. The lucky few will pitch their predictive model to expert judges and an engaged audience. They have only three minutes to present in non-technical terms three items: personal background, predictive model description, and how they would use there model to make money in finance. If their model and presentation impresses our judges, they will be eligible to work with BattleFin and Deltix to convert their predictive model into a trading strategy.
这个是Kaggle的competition,把这个东西提出来的目的是告诉大家。现在的行业趋势和技术趋势——它真的就在我们身边!说完了这三个东西,大家是怎么看、怎么想的呢?其实,这个项目的价值只有自己做下去了才知道。
关于项目中人的自我管理与自我超越
追的太紧太累,忘了自己出发的目标,要时时停下来思考。
我上学期一直埋头干,没有停下来思考;恰好在家,心态较好,所以就趁着情绪思考了我们的项目,以及它的意义。 我与吴亚林同学在假期试着做了一个东西,Quantitive-Investing,我们试着用机器学习和数据挖掘去发现资本市场的规律。由于策略定制、回测以及可视化,都是自行编写代码。这我深深感觉到,我们还差很远,真的! 我始终受到了自己眼界的限制,我以为我这样的,已算优秀;但在与别的学校同学交流后,实在惭愧和挫败。 我们需要努力,需要有目的地努力,因为时间实在太有限了。我恨自己没能早一点知道这些,没能早一天感受到自己的不足。
我们生长的环境条件不如别人
这一点,我是自找的,谁叫我高中不好好学习呢?那天我与同学聊天,他说自己的学校很垃圾,那里的老师和学生都很差劲。我没有说话,我觉得,这就是我们的出身,这是事实。但我看到我身边的同学,可以靠家教收入养活自己,可以年三十都不回家在学校学习(他成功地通过转学考试,从上海师范大学进入华东师大数学系;华东师大与纽约大学合办了“上海-纽约大学”,他有很大的机会进入这里学习,甚至去纽约大学Courant数学研究所),这就是我们能做的。
我们做事的心态和毅力不如别人
我其实并没有很努力,或者说,我并没有找清楚方向;我在浪费生命。我希望大家也能找时间,安静地思考自己喜欢的东西,然后花时间去做,去学习。这个项目里,应该可以找到自己发挥兴趣和价值的地方。 我希望大家可以多多发现项目的价值,用兴趣驱动自己,用责任支撑自己。
一点技术文献都读不过完、做不过去,一定是很失败的。谢老师很nice地让我去读文献,我花了大半个月才给她回邮件;老师让我试着写程序实现优化算法,我到现在还没开始看代码。拖延症的后果,就是我被那些事情拖住,当我面临更好的机会时,我不得不放弃:那天张老师问我是否有时间去公司实习,我没法开心起来,因为我不能答应;一方面是我要对我的队友负责,另一方面是对张老师负责。
结语
我要静下心来读书,背单词,然后超越自己!大家加油!
