用Python Requests抓取知乎用户信息(二)
2014-02-15
你可以先读一下用Python Requests抓取知乎用户信息了解文章的背景和细节;这篇文章主要关注对爬虫性能的改造。
为什么提出多线程?
这部分的知识是从麦兜兜的博客中搬过来的,例子非常棒!
为什么要提出多线程呢?我们首先看一个单线程的例子。
from time import sleep,ctime
def loop0():
print 'start loop 0 at:',ctime()
sleep(4)
print 'loop 0 done at:',ctime()
def loop1():
print 'start loop 1 at:',ctime()
sleep(2)
print 'loop 1 done at:',ctime()
def main():
print 'starting at:',ctime()
loop0()
loop1()
print 'all DONE at:',ctime()
if __name__=='__main__':
main()
运行结果:
>>>
starting at: Mon Aug 31 10:27:23 2009
start loop 0 at: Mon Aug 31 10:27:23 2009
loop 0 done at: Mon Aug 31 10:27:27 2009
start loop 1 at: Mon Aug 31 10:27:27 2009
loop 1 done at: Mon Aug 31 10:27:29 2009
all DONE at: Mon Aug 31 10:27:29 2009
>>>
可以看到单线程中的两个循环,只有一个循环结束后另一个才开始。总共用了6秒多的时间。假设两个loop中执行的不是sleep,而是一个别的运算的话,如果我们能让这些运算并行执行的话,是不是可以减少总的运行时间呢,这就是我们提出多线程的前提。
多线程改造
思路
根据文章,我们使用threading包进行多线程改造。改造的思路很简单,针对post数据中参数offset的奇偶性分成两个线程thread1和thread2即可。
一起来读代码吧
import threading
from time import ctime
def main():
# login
s.post('http://www.zhihu.com/login', login_data)
for user in user_list:
print 'crawling ' + user + '\'s followers...\n'
# 写文件
global fp
fp = codecs.open(user + '.txt', 'w', 'utf-8')
url = 'http://www.zhihu.com/people/' + user + '/followers'
# 转跳到用户followers页
r = s.get(url)
data = r.text
# 多线程
print 'starting at:',ctime()
threads = []
t = threading.Thread(target=load_more_thread1,args=(user,data))
threads.append(t)
t = threading.Thread(target=load_more_thread2,args=(user,data))
threads.append(t)
for i in range(2):
threads[i].start()
for i in range(2):
threads[i].join()
print 'all DONE at:',ctime()
细节解释
改造的关键都在多线程这里。我们首先创建了threading对象t,并添加(append)到threads中。使用threading对象的一个原因是,我在是用thread的时候输入参数时可能是因为不规范而总是出错,不过这里threading便可以很好地支持。
随后的start和join语句便会让进行开始直到全部进程结束。因此在一个for循环中我们便同时运行了thread1和thread2两个抓取程序。性能自然是提升了~
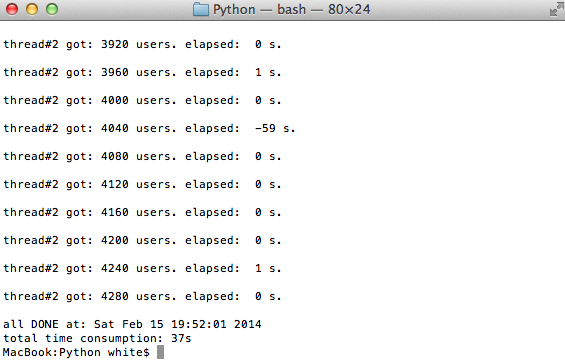
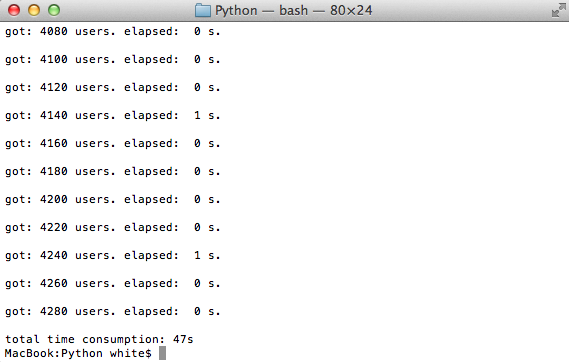
结果对比
下面我们通过程序运行时间来感受一下改进前后的情况:
多(双)线程
单线程
结语
做事情就是这样,遇到效果不满意、或是需要改进的时候,如果对项目本身,或是技术原理有认识,那么操作起来就会事半功倍;这也是我为什么想读博的原因吧!
